#========================================#
# Importing required libraries #
#========================================#
import dlt
import duckdb
import os
import logging
from pathlib import Path
import dotenv
# ======================================== #
# Logging Setup #
# ======================================== #
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | [%(levelname)s] | %(message)s",
)
log = logging.getLogger(__name__)
# ======================================== #
# Environment Setup (.env for Postgres) #
# ======================================== #
dotenv.load_dotenv()
connection_string = os.getenv("POSTGRES_CONNECTION_STRING")
if not connection_string:
raise ValueError(" Missing POSTGRES_CONNECTION_STRING in your .env file!")
pg_destination = dlt.destinations.postgres(connection_string)
# ======================================== #
# Directory Setup #
# ======================================== #
base_dir = Path(__file__).resolve().parent
data_dir = base_dir / "Data"
fact_folder = data_dir / "fact_db"
customer_folder = data_dir / "customer"
location_folder = data_dir / "location"
# Ensure staging truncation
dlt.config["load.truncate_staging_dataset"] = True
# ======================================== #
# DLT Resources #
# ======================================== #
@dlt.resource(table_name="loans", write_disposition="replace")
def loans():
query = f"""
SELECT *
FROM read_csv_auto('{os.path.join(fact_folder, "*.csv")}',
union_by_name = true,
filename = true)
"""
con = duckdb.connect()
con.execute(query)
chunk_size = 10000
while True:
chunk = con.fetch_df_chunk(chunk_size)
if chunk is None or chunk.empty:
break
for record in chunk.to_dict(orient="records"):
yield record
@dlt.resource(table_name="customers", write_disposition="replace")
def customers():
query = f"""
SELECT *
FROM read_csv_auto('{os.path.join(customer_folder, "*.csv")}',
union_by_name = true,
filename = true)
"""
con = duckdb.connect()
con.execute(query)
chunk_size = 10000
while True:
chunk = con.fetch_df_chunk(chunk_size)
if chunk is None or chunk.empty:
break
for record in chunk.to_dict(orient="records"):
yield record
@dlt.resource(table_name="location", write_disposition="replace")
def locations():
query = f"""
SELECT *
FROM read_csv_auto('{os.path.join(location_folder, "*.csv")}',
union_by_name = true,
filename = true)
"""
con = duckdb.connect()
con.execute(query)
chunk_size = 10000
while True:
chunk = con.fetch_df_chunk(chunk_size)
if chunk is None or chunk.empty:
break
for record in chunk.to_dict(orient="records"):
yield record
@dlt.source
def source():
return [loans(), customers(), locations()]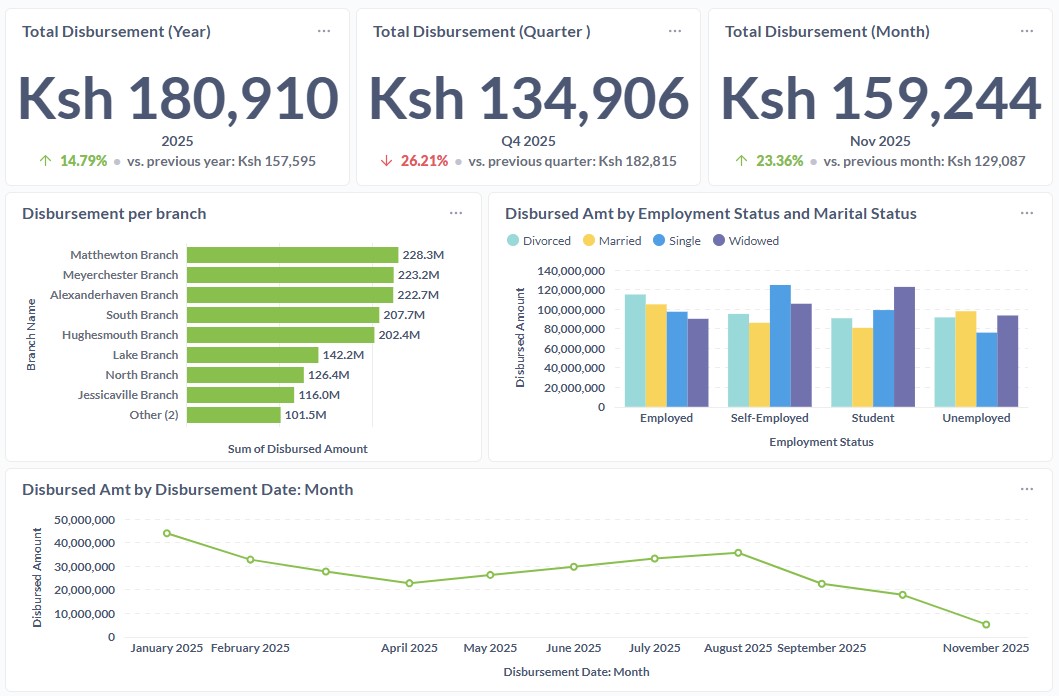
Overview
In the rapidly evolving financial sector, managing loan portfolios effectively is crucial for minimizing defaults and maximizing returns. This project presents a comprehensive solution that leverages modern data stack technologies to enhance loan portfolio management for financial institutions. We created an automated pipeline that provides real-time insights into portfolio health by integrating tools such as duckdb for data extraction, dlt for data loading, PostgreSQL for data storage, dbt for data transformation, Dagster for orchestration, and Metabase for visualization. This solution not only improves risk assessment and monitoring but also enables data-driven decision-making, ultimately leading to better financial outcomes.
Note
This dashboard is purely for demonstration purposes. All data presented here were synthetically generated using Python’s Faker library to simulate realistic loan records. These figures do not represent real customers or production data.
For access to a live dashboard please Contact.
Problem definition
Financial institutions often struggle with managing loan portfolios effectively, leading to increased default rates and financial losses. The challenge lies in accurately assessing borrower risk, monitoring portfolio health, and making informed lending decisions in real-time.
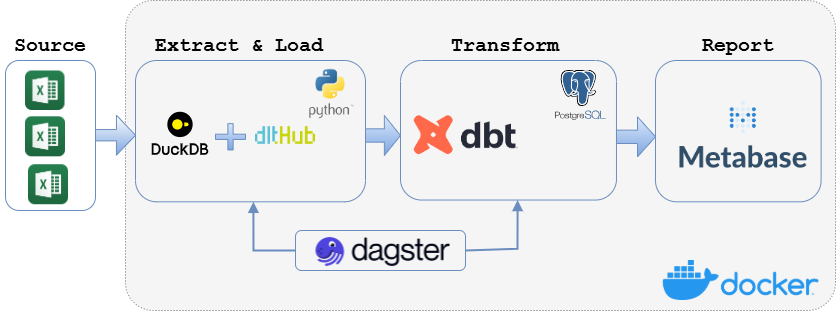
To address these challenges, we designed a robust ELT (Extract, Load, Transform) architecture that automates data processing and provides actionable insights. The architecture consists of the following key components:
Data Extraction and Loading: Utilized
duckdbto efficiently query and merge multiple CSV files from local folders, followed by loading the consolidated data into a PostgreSQL database using thedltlibrary.Data Transformation: Implemented
dbtto clean, structure, and prepare the data for analysis, following the medallion architecture (bronze, silver, gold layers).Orchestration: Employed
Dagsterto automate and schedule the entire data pipeline, ensuring seamless integration between extraction, transformation, and loading processes.Visualization: Leveraged
Metabaseto create interactive dashboards that provide real-time insights into loan portfolio health, enabling stakeholders to make informed decisions.Containerization: Used
Dockerto containerize the entire data stack, ensuring portability and ease of deployment across different environments.
The following diagram illustrates the overall ELT architecture employed in this project:
ELT architecture overview
Data Extraction and Loading
The first step in our pipeline involved extracting data from local spreadsheet folders (3 source folders were used), including customers folder, location folder, and loan details folder. We utilized an open-source, in-process Online Analytical Processing (OLAP) database management system (duckdb) to query multiple csv files from each folder by merging them using attribute names through efficient analytical duckdb queries. This approach streamlined data extraction (the “E” (Extract) in ELT) , ensuring consistency and reliability across the merged datasets.
After consolidating multiple CSV files, the unified dataset (per folder) was ingested into a PostgreSQL database using the data load tool (dlt). This open-source Python library simplifies data pipelines by automating the “L” (Load) in ELT workflows, making it fast and reliable to handle raw data.
TipData Extraction & Loading Implementation Snippet
CautionExpand to explore other file formats DuckDB can directly query using SQL functions
File Formats:
Parquet,CSV,JSON,Excel (.xlsx files),Text files,Blob files, andZIP archives.In-Memory Data:
Pandas DataFrames,NumPy arrays,Polars DataFrames, andApache Arrow tables.Databases:
PostgreSQL,MySQL,SQLite, andOther DuckDB.Cloud and Remote Storage:
Amazon S3,Google Cloud Storage (GCS),Azure Blob Storage, andHDFS.Web Data:
Web APIsandHTTP/HTTPS URLs.Geospatial Data:
GeoJSONandShapefiles.Data Lake Formats:
Delta LakeandIceberg.
Ref: DuckDB Documentation
Data Transformation with dbt
After loading, the data was transformed using dbt, an open-source SQL-based tool that lets analysts and engineers clean, structure, and prepare data directly in their warehouse. In ELT workflows, dbt handles the “T” (Transform), turning raw data into analysis-ready datasets.
Using dbt allowed modular, reusable transformation logic (See Tip 1). The pipeline followed the medallion architecture where each layer was generated from the previous one, ensuring reliability, reusability, and analytical readiness. The layers included:
- Bronze (staging): Cleans raw data.
- Silver (intermediate): Standardizes and enriches data.
- Gold (marts): Produces aggregated, business-ready insights.
Tipdbt project configuration snippet
#=========================================#
# dbt_project.yml #
#=========================================#
name: 'postgres_dbt'
version: '1.0.0'
profile: 'postgres_dbt'
# Model configurations
models:
postgres_dbt:
src:
+schema: transformed
+materialized: ephemeral
dim:
+schema: transformed
+materialized: table
fct:
+schema: transformed
+materialized: table
marts:
+schema: analytics
+materialized: table1. Source Definition & Staging Layer
Purpose: Acts as the bronze layer, ensuring that raw ingested data tables (declared in
sources.ymlfile) is properly registered, validated, and queryable in dbt.
This layer defines the source tables ingested into PostgreSQL via dlt, enabling dbt to reference and transform them in subsequent models. The source tables include customer, loans, and location. In this project, we combined source and staging layer to ingest and perform preliminary raw data cleaning from the source tables (customer, loans, location), with minimal cleaning and schema alignment via SQL files.
Note
In a production scenario, the staging layer would typically involve more extensive data validation, cleansing, and transformation to ensure data quality before progressing to the silver layer. Therefore it is recommended to separate source definitions and staging transformations into distinct layers for better maintainability and clarity.
TipSource Definition Snippet
#========================================#
# sources.yml #
#========================================#
sources:
- name: portfolio_data
schema: staging
description: "Raw data ingested from DLT pipeline containing customers, loans, and location tables."
tables:
- name: customers
description: "Raw customer-level information."
meta:
dagster:
asset_key: ["dlt_source_customers"]
- name: loans
description: "Raw loan-level portfolio data."
meta:
dagster:
asset_key: ["dlt_source_loans"]
- name: location
description: "Raw location and relationship manager data."
meta:
dagster:
asset_key: ["dlt_source_locations"]
TipSource Table Reference & Staging Layer Implementation Snippet
--========================================
-- customer.sql
--========================================
with customers as (
select *
from {{ source('portfolio_data', 'customers') }}
)
select
-- Convert customer ID to lowercase to ensure consistent format
TRIM(UPPER(customer_id)) as customer_id,
-- Clean and standardize customer name
initcap(trim(customer_name)) as customer_name,
-- Normalize gender
TRIM(UPPER(gender)) as gender,
-- standardize date of birth
CASE
WHEN dob::text ~ '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
THEN dob::date
ELSE NULL
END AS dob,
-- Clean and standardize categorical fields
trim(initcap(marital_status)) as marital_status,
trim(initcap(employment_status)) as employment_status,
-- Normalize income bracket
trim(income_bracket) as income_bracket,
-- Format region names uniformly
trim(initcap(region)) as region,
-- Cast credit score to integer
cast(credit_score as int) as credit_score
from customers
--========================================
-- location.sql
--========================================
with locations as (
select *
from {{ source('portfolio_data', 'location') }}
)
SELECT
TRIM(UPPER(branch_id)) AS branch_id,
trim(initcap(branch_name)) AS branch_name,
trim(initcap(region)) AS region,
trim(initcap(country)) AS country,
trim(initcap(manager_name)) AS manager_name,
CASE
WHEN opened_date::text ~ '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
THEN opened_date::date
ELSE NULL
END AS opened_date,
trim(initcap(branch_type)) AS branch_type
FROM locations
--========================================
-- loans.sql
--========================================
with loans as (select * from {{ source('portfolio_data', 'loans') }})
SELECT
TRIM(UPPER(loan_id)) AS loan_id,
TRIM(UPPER(customer_id)) AS customer_id,
TRIM(UPPER(branch_id)) AS branch_id,
trim(initcap(loan_product)) AS loan_product,
CASE
WHEN disbursement_date::text ~ '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
THEN disbursement_date::date
ELSE NULL
END AS disbursement_date,
CASE
WHEN maturity_date::text ~ '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
THEN maturity_date::date
ELSE NULL
END AS maturity_date,
CAST(loan_amount AS NUMERIC(12,2)) AS loan_amount,
CAST(interest_rate AS NUMERIC(5,2)) AS interest_rate,
CAST(installment_amount AS NUMERIC(12,2)) AS installment_amount,
CAST(outstanding_balance AS NUMERIC(12,2)) AS outstanding_balance,
CAST(loan_status AS VARCHAR) AS loan_status,
CAST(days_past_due AS NUMERIC(6,2)) AS days_past_due,
CAST(amount_overdue AS NUMERIC(12,2)) AS amount_overdue,
CASE
WHEN delinquency_start_date::text ~ '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
THEN delinquency_start_date::date
ELSE NULL
END AS delinquency_start_date,
CAST(default_flag AS INT) AS default_flag
FROM loans2. Transformation Layer (Dimensional & Fact Models)
Purpose: Serves as the silver layer, transforming raw data into structured and analysis-ready tables.
This layer transforms the cleaned staging data into structured, analysis-ready datasets. It includes dimension models (customer and location tables) and a fact model (loan table). The dimension models in this project standardized and enriched customer and location data, while the fact model consolidated loan details with calculated fields for delinquency analysis.
TipTransformation Layer Implementation Snippet
--========================================
-- Transformation Model: customer.sql
--========================================
with customers as (
select *
from {{ ref('src_customer') }}
where customer_id is not null -- Exclude invalid records
and trim(cast(customer_id as text)) <> '' -- Exclude empty strings if any
)
select
-- create a consistent surrogate key
{{ dbt_utils.generate_surrogate_key(['customer_id']) }} as sur_customer_id,
-- clean and standardized fields
customer_id,
initcap(trim(customer_name)) as customer_name,
case
when gender = 'MALE' then 'Male'
when gender = 'FEMALE' then 'Female'
else 'Unknown'
end as gender,
dob,
marital_status,
employment_status,
income_bracket,
region,
credit_score
from customers
--========================================
-- Transformation Model: location.sql
--========================================
with locations as (
select *
from {{ ref('src_location') }}
where branch_id is not null -- Exclude invalid records
and trim(cast(branch_id as text)) <> '' -- Exclude empty strings if any
)
select
-- create a consistent surrogate key
{{ dbt_utils.generate_surrogate_key(['branch_id']) }} as branch_id_sur,
-- original fields
branch_id,
branch_name,
region,
country,
manager_name,
opened_date,
branch_type
from locations
--========================================
-- Transformation Model: loans.sql
--========================================
with loans as (
select *
from {{ ref('src_loans') }}
where loan_id is not null -- Exclude invalid records
and trim(cast(loan_id as text)) <> '' -- Exclude empty strings if any
)
select
-- create consistent surrogate keys
{{ dbt_utils.generate_surrogate_key(['loan_id']) }} as sur_loan_id,
{{ dbt_utils.generate_surrogate_key(['customer_id']) }} as sur_customer_id,
{{ dbt_utils.generate_surrogate_key(['branch_id']) }} as sur_branch_id,
-- attributes
loan_id,
customer_id,
branch_id,
loan_product,
disbursement_date,
maturity_date,
loan_amount,
interest_rate,
installment_amount,
outstanding_balance,
loan_status,
days_past_due as days_late,
CASE WHEN days_past_due < 1 THEN days_past_due ELSE NULL END AS PAR_0,
CASE WHEN days_past_due >= 1 AND days_past_due < 30 THEN days_past_due ELSE NULL END AS PAR_30,
CASE WHEN days_past_due >= 30 AND days_past_due < 60 THEN days_past_due ELSE NULL END AS PAR_60,
CASE WHEN days_past_due >= 60 THEN days_past_due ELSE NULL END AS PAR_90,
amount_overdue,
delinquency_start_date,
default_flag
from loans3. Marts Layer
Purpose: Acts as the gold layer, delivering curated datasets for analytics and reporting.
This project utilized this layer to create business-facing datasets for analytics and machine learning data models. It consolidated dimension and fact models into an analytics table that supported Metabase dashboards and generated feature tables for ML models predicting loan defaults (future work).
TipMarts Layer Implementation Snippet
--========================================
-- Analytics Model: Analytics.sql
--========================================
WITH
-- Dimension tables
dim_customers AS (
SELECT
customer_id,
customer_name,
gender,
dob,
marital_status,
employment_status,
income_bracket
FROM {{ ref('customers') }}
),
dim_location AS (
SELECT
branch_id,
branch_name,
region,
country,
manager_name,
opened_date,
branch_type
FROM {{ ref('location') }}
),
-- Fact table (transactional data)
fact_loans AS (
SELECT
loan_id,
customer_id,
branch_id,
loan_product,
disbursement_date,
maturity_date,
loan_amount AS disbursed_amt,
outstanding_balance AS outstanding_bal,
loan_status,
interest_rate,
days_late,
par_0,
par_30,
par_60,
par_90,
amount_overdue,
delinquency_start_date
FROM {{ ref('fact_tables') }}
)
-- === STAR JOIN ===
SELECT
-- Key alignment
f.customer_id AS fact_customer_id,
c.customer_id AS dim_customer_id,
f.branch_id AS fact_branch_id,
o.branch_id AS dim_branch_id,
f.loan_id,
-- Customer attributes
c.customer_name,
c.gender,
c.marital_status,
c.employment_status,
c.income_bracket,
-- Location attributes
o.branch_name,
o.region,
o.country,
o.manager_name,
o.branch_type,
-- Loan attributes
f.loan_product,
f.disbursement_date,
f.maturity_date,
f.disbursed_amt,
f.outstanding_bal,
f.interest_rate,
f.loan_status,
f.days_late,
f.par_0,
f.par_30,
f.par_60,
f.par_90,
f.amount_overdue,
f.delinquency_start_date,
-- Loan status flag
CASE
WHEN f.days_late >= 60 THEN 1
ELSE 0
END AS default_status,
-- Portfolio at Risk (PAR) ratio
ROUND(
COALESCE(f.par_30 + f.par_60 + f.par_90, 0)::NUMERIC
/ NULLIF(f.outstanding_bal, 0),
4
) AS portfolio_at_risk_ratio,
-- Derived time dimensions
EXTRACT(YEAR FROM f.disbursement_date) AS disbursement_year,
EXTRACT(MONTH FROM f.disbursement_date) AS disbursement_month,
-- Ranking by disbursement period
DENSE_RANK() OVER (
ORDER BY
EXTRACT(YEAR FROM f.disbursement_date),
EXTRACT(MONTH FROM f.disbursement_date)
) AS disbursement_month_rank
FROM fact_loans f
INNER JOIN dim_customers c
ON f.customer_id = c.customer_id
INNER JOIN dim_location o
ON f.branch_id = o.branch_id
--========================================
-- ML Model: training.sql
--========================================
{% set train_start = '2022-01-01' %}
{% set train_end = '2024-12-31' %}
{% set observation_window_months = 6 %}
WITH training AS (
SELECT
--ID columns
f.fact_customer_id,
f.dim_customer_id,
f.fact_branch_id,
f.dim_branch_id,
-- Loan details
f.loan_id,
f.loan_product,
f.disbursement_date,
f.disbursed_amt,
f.outstanding_bal,
f.interest_rate,
-- Customer attributes
f.gender,
f.marital_status,
f.employment_status,
f.income_bracket,
-- Branch attributes
f.region,
f.branch_type,
-- Loan performance metrics
f.days_late,
f.par_0,
f.par_30,
f.par_60,
f.par_90,
-- Target variable (label)
f.default_status AS target_default,
-- Derived date fields
f.disbursement_month,
f.disbursement_year
FROM {{ ref('analytics') }} AS f
WHERE
f.disbursement_date BETWEEN '{{ train_start }}' AND '{{ train_end }}'
-- Ensure at least full observation period before today
-- We only want to include loans that have had enough time to observe default behavior
AND f.disbursement_date <= CURRENT_DATE - INTERVAL '{{ observation_window_months }} months'
)
SELECT *
FROM training
--========================================
-- ML Model: testing.sql
--========================================
-- Testing/Evaluation set: loans disbursed from 2025-01-01 to 2025-10-01
-- Must have full 6-month observation window
{% set test_start = '2025-01-01' %}
{% set test_end = '2025-10-01' %}
{% set observation_window_months = 6 %}
WITH testing AS (
SELECT
-- ID columns
f.fact_customer_id,
f.dim_customer_id,
f.fact_branch_id,
f.dim_branch_id,
-- Core loan attributes
f.loan_id,
f.loan_product,
f.disbursement_date,
f.disbursed_amt,
f.outstanding_bal,
f.interest_rate,
-- Customer attributes
f.gender,
f.marital_status,
f.employment_status,
f.income_bracket,
-- Branch attributes
f.region,
f.branch_type,
-- Performance metrics and target label
f.days_late,
f.par_0,
f.par_30,
f.par_60,
f.par_90,
f.default_status AS target_default,
-- Derived date fields
f.disbursement_month,
f.disbursement_year
FROM {{ ref('analytics') }} AS f
WHERE
f.disbursement_date BETWEEN '{{ test_start }}' AND '{{ test_end }}'
-- Ensure full observation period (at least 6 months since disbursement)
AND f.disbursement_date <= CURRENT_DATE - INTERVAL '{{ observation_window_months }} months'
)
SELECT *
FROM testing
--========================================
-- ML Model: inference.sql
--========================================
-- Inference set: NEW loans disbursed in November 2025
-- These loans have no target label (yet)
-- Only include features known at disbursement
{% set inference_month_start = '2025-11-01' %}
{% set inference_month_end = '2025-11-30' %}
WITH inference AS (
SELECT
-- ID columns
f.fact_customer_id,
f.dim_customer_id,
f.fact_branch_id,
f.dim_branch_id,
-- Loan details
f.loan_id,
f.loan_product,
f.disbursement_date,
f.disbursed_amt,
f.outstanding_bal,
f.interest_rate,
-- Customer attributes
f.gender,
f.marital_status,
f.employment_status,
f.income_bracket,
-- Location attributes
f.region,
f.branch_type,
-- Derived date columns
f.disbursement_month,
f.disbursement_year
FROM {{ ref('analytics') }} AS f
WHERE
f.disbursement_date BETWEEN '{{ inference_month_start }}' AND '{{ inference_month_end }}'
-- Exclude any loans already defaulted (we only want active/new)
AND f.default_status = 0
)
SELECT *
FROM inference
Tip 1: SQL Templating with Jinja
Jinja templating throughout the models ensured dynamic SQL, avoiding code duplication, and guaranteed scalability and consistency across the pipeline.
Orchestration with Dagster
To automate the entire data pipeline, we employed Dagster, a powerful orchestration tool. Dagster enabled the definition and scheduling of workflows that encompass data extraction, transformation, and loading processes. By setting up Dagster jobs ensured that the pipeline runs seamlessly and consistently, providing up-to-date insights into the loan portfolio. The figure below illustrates the Dagster pipeline architecture used in this project.
Dagster Pipeline Visualization:

TipPipeline Orchestration with Dagster Snippet
# ==================== #
# Imports #
# ==================== #
from pathlib import Path
import sys
import os
import logging
from dotenv import load_dotenv
import dlt
import dagster as dg
from dagster_dlt import DagsterDltResource, dlt_assets
from dagster_dbt import DbtCliResource, dbt_assets, DbtProject
# ==================== #
# Logging Setup #
# ==================== #
BASE_DIR = Path(__file__).parents[1]
LOGS_DIR = BASE_DIR / "logs"
LOGS_DIR.mkdir(exist_ok=True)
log_file = LOGS_DIR / "dagster_orchestration.log"
logging.basicConfig(
filename=log_file,
level=logging.INFO,
format="%(asctime)s | [%(levelname)s] | %(message)s",
)
console = logging.StreamHandler()
console.setLevel(logging.INFO)
console.setFormatter(logging.Formatter("%(asctime)s | [%(levelname)s] | %(message)s"))
logging.getLogger().addHandler(console)
logging.info(" Starting Dagster orchestration setup...")
# ==================== #
# Setup #
# ==================== #
# Add ETL base directory to sys.path for imports
sys.path.insert(0, str(BASE_DIR))
from data_extraction.load_data import source # Import the source function
logging.info(" Imported DLT source from data_extraction.load_data")
# Load environment variables from .env file
ENV_PATH = BASE_DIR / ".env"
load_dotenv(dotenv_path=ENV_PATH)
connection_string = os.getenv("POSTGRES_CONNECTION_STRING")
if not connection_string:
logging.error(" Missing POSTGRES_CONNECTION_STRING in .env file")
raise ValueError("Missing POSTGRES_CONNECTION_STRING in .env")
logging.info(f" Using PostgreSQL connection: {connection_string}")
# Initialize Dagster DLT resource
dlt_resource = DagsterDltResource()
# ==================== #
# DLT ASSET #
# ==================== #
@dlt_assets(
dlt_source=source(),
dlt_pipeline=dlt.pipeline(
pipeline_name="loans_pipeline",
dataset_name="staging",
destination=dlt.destinations.postgres(connection_string)
),
)
def dlt_load(context: dg.AssetExecutionContext, dlt: DagsterDltResource):
"""Load local CSVs (customers, loans, location) into PostgreSQL via DLT pipeline."""
logging.info(" [DLT] Starting pipeline execution through Dagster...")
try:
yield from dlt.run(context) # Execute the DLT pipeline
logging.info(" [DLT] Pipeline completed successfully via Dagster.")
except Exception as e:
logging.exception(f" [DLT] Pipeline execution failed: {e}")
raise
# ==================== #
# DBT ASSET #
# ==================== #
dbt_project_dir = BASE_DIR / "postgres_dbt"
profiles_dir = dbt_project_dir # profiles.yml is here
dbt_project = DbtProject(project_dir=dbt_project_dir, profiles_dir=profiles_dir)
dbt_resource = DbtCliResource(project_dir=dbt_project_dir, profiles_dir=profiles_dir)
dbt_project.prepare_if_dev()
logging.info(" [DBT] Project and profiles initialized successfully")
@dbt_assets(manifest=dbt_project.manifest_path)
def dbt_models(context: dg.AssetExecutionContext, dbt: DbtCliResource):
"""Run and expose all dbt models (staging → transformed → marts)."""
logging.info(" [DBT] Running dbt build...")
try:
yield from dbt.cli(["build"], context=context).stream()
logging.info(" [DBT] dbt build completed successfully.")
except Exception as e:
logging.exception(f" [DBT] dbt build failed: {e}")
raise
# ==================== #
# JOBS #
# ==================== #
# Define a job for DLT loading
job_dlt = dg.define_asset_job(
"job_dlt",
selection=dg.AssetSelection.keys(
"dlt_source_loans", # These are the actual asset keys created by @dlt_assets
"dlt_source_customers",
"dlt_source_locations"
),
)
# Define a job for dbt transformations
job_dbt = dg.define_asset_job(
"job_dbt",
selection=dg.AssetSelection.key_prefixes("staging", "transformed", "marts")
)
# ==================== #
# SCHEDULES #
# ==================== #
schedule_dlt = dg.ScheduleDefinition(
job=job_dlt,
cron_schedule="10 1 * * *" # 01:10 UTC = 04:10 Nairobi
)
logging.info("Dagster schedule created for job_dlt (daily 04:10 Nairobi)")
# ==================== #
# SENSORS #
# ==================== #
@dg.multi_asset_sensor(
monitored_assets=[
dg.AssetKey("dlt_source_customers"),
dg.AssetKey("dlt_source_loans"),
dg.AssetKey("dlt_source_locations"),
],
job=job_dbt,
)
def dlt_load_sensor(context):
"""Trigger dbt job after all DLT ingestion assets complete."""
logging.info("⚡ Sensor triggered: DLT assets finished loading. Launching dbt job...")
yield dg.RunRequest(run_key=None)
# ==================== #
# DEFINITIONS #
# ==================== #
defs = dg.Definitions(
assets=[dlt_load, dbt_models],
resources={"dlt": dlt_resource, "dbt": dbt_resource},
jobs=[job_dlt, job_dbt],
schedules=[schedule_dlt],
sensors=[dlt_load_sensor]
)
logging.info(" Dagster definitions initialized successfully.")
logging.info(" Dagster orchestration setup complete — ready for `dagster dev`.")Dockerization
To ensure that our data stack is portable and easy to deploy, we containerized each component using Docker. This approach allowed us to package the PostgreSQL database, dbt transformations, Dagster orchestration, and Metabase visualization into containers. Docker Compose was employed to manage multi-container applications, allowing us to define and run the entire data stack with a single command. This setup not only simplified deployment but also enhanced scalability and maintainability.
TipDocker Compose Snippet
#========================================#
# docker-compose.yml #
#========================================#
services:
dwh_pipeline:
build:
context: .
dockerfile: Dockerfile.dwh
container_name: dwh_pipeline
env_file:
- .env
environment:
CREDENTIALS__CONNECTION_STRING: ${POSTGRES_CONNECTION_STRING}
DBT_HOST: ${DBT_HOST}
DBT_USER: ${DBT_USER}
DBT_PASSWORD: ${DBT_PASSWORD}
DBT_PORT: ${DBT_PORT}
DBT_DBNAME: ${DBT_DBNAME}
DBT_SCHEMA: ${DBT_SCHEMA}
volumes:
# Existing data mount
- ./data_extraction/Data:/pipeline/data_extraction/Data
# Additional volumes for runtime editing and live data
- ./data_extraction:/pipeline/data_extraction
- ./postgres_dbt:/pipeline/postgres_dbt
- ./orchestration:/pipeline/orchestration
# Mount dbt profile directly
- ./postgres_dbt/profiles.yml:/root/.dbt/profiles.yml
# Mount global data directory
- ./data:/pipeline/data
# Mount requirements file for live dependency changes
- ./requirements.txt:/pipeline/orchestration/requirements.txt
# Mount .env file for consistent runtime environment
- ./.env:/pipeline/.env
expose:
- 3001
depends_on:
- postgres_etl
networks:
- dokploy-network
labels:
# Network labels are deliberately removed for security purposes
postgres_etl:
image: postgres:latest
container_name: postgres_etl
environment:
POSTGRES_USER: ${DBT_USER}
POSTGRES_DB: ${DBT_DBNAME}
POSTGRES_PASSWORD: ${DBT_PASSWORD}
volumes:
- etl_pgdata:/var/lib/postgresql/data
networks:
- dokploy-network
volumes:
etl_pgdata:
networks:
dokploy-network:
external: true
Note
Contact to access the deployed warehouse pipeline.
Conclusion
This project demonstrates the effectiveness of a modern data stack in managing loan portfolios for financial institutions. By integrating PostgreSQL, dbt, Dagster, and Metabase, we created an automated pipeline that enhances data management, transformation, and visualization. The solution provides real-time insights into portfolio health, enabling better risk assessment and decision-making. Future work will focus on incorporating machine learning models to predict borrower defaults to further enhance portfolio management strategies.
Future Work
Future enhancements to this project could include the integration of machine learning algorithms to predict loan defaults based on historical data. Additionally, expanding the data sources to include alternative credit data and social media insights could provide a more comprehensive view of borrower risk. Implementing advanced analytics and reporting features in Metabase would also enhance the user experience and provide deeper insights into portfolio performance.
Acknowledgments
I would like to express my gratitude to the open-source community for providing the tools and resources that made this project possible. Special thanks to the developers of PostgreSQL, dbt, Dagster, and Metabase for their continuous efforts in advancing data management and analytics.